Thiết lập kỳ vọng thực tế cho LLM cục bộ trên Linux 8GB RAM
Trước khi đi sâu vào chi tiết, hãy nói thẳng: một chiếc laptop chạy Linux Mint với 8GB RAM hoàn toàn có thể chạy các LLM cục bộ. Tuy nhiên, đừng mong nó 'cân' mọi mô hình phức tạp mà bạn thấy trên Reddit. Đây không phải là phương pháp 'brute force' mà là tối ưu hóa thông minh.

Với cấu hình phần cứng như vậy, hiệu năng ổn định mà bạn có thể mong đợi:
- Các mô hình 3B đến 4B chạy mượt mà, gần như không có độ trễ đáng kể.
- Mô hình 7B là khả thi, nhưng bạn sẽ cảm nhận được sự nặng nề và chậm hơn rõ rệt.
- Mọi thứ lớn hơn 7B sẽ bắt đầu thử thách lòng kiên nhẫn của bạn và khả năng tản nhiệt của máy.
Tin tốt là các mô hình nhỏ ngày nay đã mạnh hơn rất nhiều. Một mô hình 3B được tinh chỉnh tốt vẫn cực kỳ hiệu quả cho các tác vụ hàng ngày như soạn thảo, tóm tắt, động não ý tưởng, và hỗ trợ lập trình cơ bản.
Về GPU, với đồ họa tích hợp AMD trên Linux Mint, phương pháp ít phiền toái nhất hiện nay là tận dụng suy luận CPU với các mô hình lượng tử hóa. Nghe có vẻ không 'ngầu', nhưng nó mang lại sự ổn định và khả năng dự đoán cao. Đối với một chiếc máy tính sử dụng hàng ngày, sự ổn định đó là vàng.
Tối ưu hóa bộ nhớ: Bước đầu tiên quan trọng để chạy LLM mượt mà
Đừng bỏ qua bước này, nó quyết định trải nghiệm của bạn!
Hầu hết các hướng dẫn cài đặt LLM thường bỏ qua bước quan trọng này, khiến nhiều người tự hỏi tại sao chiếc laptop tốt của họ lại đột nhiên ì ạch. Vấn đề nằm ở chỗ, các LLM cục bộ sẽ đẩy hệ thống 8GB RAM vào tình trạng quá tải bộ nhớ nhanh hơn bạn tưởng.

Trên một chiếc laptop Mint, tôi đã thấy swapfile hoạt động không ổn định ngay cả trong sử dụng desktop thông thường. Việc tải một mô hình LLM chỉ làm vấn đề trở nên trầm trọng hơn. Hai điều chỉnh nhỏ sau đây đã tạo ra sự khác biệt cực lớn:
- Tăng kích thước swapfile: Mở rộng swapfile từ khoảng 2GB lên 8GB sẽ cung cấp cho hệ thống không gian thở cần thiết khi các mô hình đột ngột ngốn bộ nhớ. Đây là một 'phao cứu sinh' cho RAM của bạn.
- Bật zram: zram tạo ra một swapfile được nén ngay trong RAM, giúp làm mượt các đợt quá tải bộ nhớ ngắn hạn. Trên các hệ thống dựa trên Ubuntu như Mint, việc cài đặt gói 'zram-tools' thường là đủ để kích hoạt nó.
Lưu ý, những tinh chỉnh này không biến laptop của bạn thành một máy trạm cao cấp. Mục đích chính là ngăn chặn những khoảnh khắc hệ thống đột ngột trở nên không phản hồi, mang lại trải nghiệm ổn định và dễ chịu hơn.
Ollama: Giải pháp đơn giản nhất để khởi động LLM cục bộ trên Linux
Đây là cách nhanh nhất để bắt đầu mà không đau đầu

Có vô số cách để chạy LLM cục bộ trên Linux. Một số mạnh mẽ, một số mang tính học thuật, và một số khác là cách tuyệt vời để bạn dành cả buổi tối tìm lỗi dependency. Nếu mục tiêu của bạn là có một 'ChatGPT' cục bộ hoạt động trơn tru trên Mint mà không vướng mắc, Ollama là lựa chọn hàng đầu hiện nay.
Quá trình cài đặt cực kỳ đơn giản:
curl -fsSL https://ollama.com/install.sh | shSau khi cài đặt xong, hãy kiểm tra ngay với một mô hình nhỏ để đảm bảo mọi thứ hoạt động:
ollama run llama3.2:3bNếu mọi thứ kết nối đúng, bạn sẽ thấy một phiên trò chuyện cục bộ ngay trong terminal. Đây là bài kiểm tra quan trọng: nếu phản hồi được truyền tải với tốc độ hợp lý, phần cứng của bạn đã sẵn sàng. Điều khiến Ollama thân thiện đến vậy là nó tự động xử lý việc tải xuống, định dạng và phân phối mô hình, biến một quá trình phức tạp thành một vài dòng lệnh đơn giản.
Tích hợp Open WebUI: Biến LLM cục bộ thành trải nghiệm ChatGPT hoàn chỉnh
Đây là lúc mọi thứ trở nên thực sự hữu ích, không còn chỉ là thử nghiệm trên terminal

Trò chuyện qua terminal rất tuyệt để thử nghiệm, nhưng không thực sự lý tưởng cho việc sử dụng hàng ngày, trừ khi bạn là một fan cứng của màn hình đen. Open WebUI, được xây dựng trên nền tảng Ollama, cung cấp chính xác những gì hầu hết mọi người mong muốn: một giao diện trình duyệt sạch sẽ, lịch sử hội thoại, và khả năng chuyển đổi mô hình dễ dàng. Nói cách khác, bạn có một trải nghiệm giống ChatGPT, nhưng hoàn toàn chạy trên máy tính của mình.
Nếu Docker đã được cài đặt trên hệ thống Mint của bạn, việc khởi chạy Open WebUI chỉ mất vài giây:
docker run -d \ -p 3000:8080 \ --name open-webui \ --restart always \ --add-host=host.docker.internal:host-gateway \ -e OLLAMA_BASE_URL=http://host.docker.internal:11434 \ -v open-webui:/app/backend/data \ ghcr.io/open-webui/open-webui:mainSau đó, chỉ cần mở trình duyệt và truy cập:
http://localhost:3000Tạo tài khoản, chọn mô hình yêu thích, và đột nhiên chiếc laptop Linux Mint bình thường của bạn đã biến thành một trợ lý AI cá nhân mạnh mẽ. Đây là khoảnh khắc mà toàn bộ thiết lập chuyển từ lý thuyết sang thực tế, trở nên cực kỳ hữu ích.
Lựa chọn mô hình LLM phù hợp với 8GB RAM: Chìa khóa thành công
Việc lựa chọn mô hình quan trọng hơn bất cứ yếu tố nào khác trên một hệ thống 8GB RAM. Chọn mô hình quá lớn, trải nghiệm sẽ nhanh chóng xuống cấp. Đưa ra lựa chọn khôn ngoan, bạn sẽ ngạc nhiên về độ mượt mà của nó.
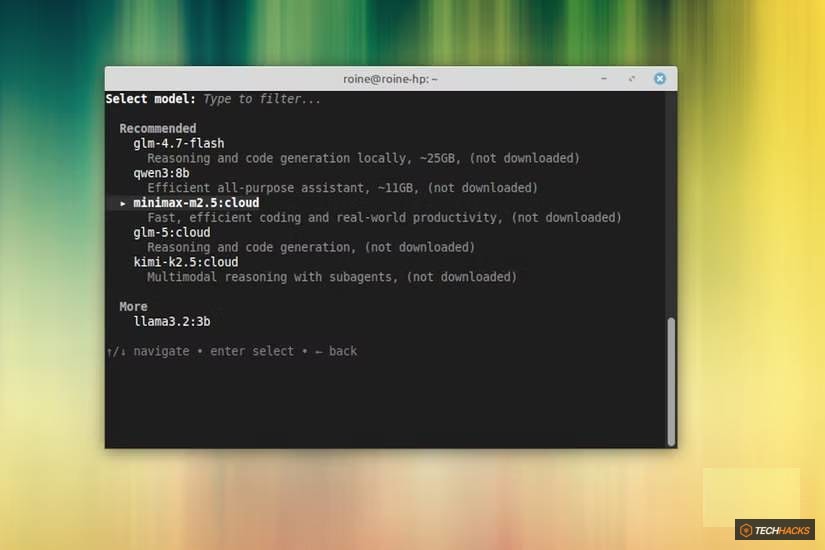
Đối với laptop dùng chip Ryzen và 8GB RAM, các mô hình sau đây thường mang lại hiệu suất tốt nhất:
- Llama 3.2 3B instruct: Một lựa chọn cân bằng tốt giữa khả năng phản hồi và chất lượng đầu ra.
- Qwen 2.5 3B instruct: Cung cấp hiệu suất cạnh tranh, rất đáng để thử.
- Phi 3 Mini: Một mô hình nhỏ gọn nhưng mạnh mẽ, lý tưởng cho phần cứng hạn chế.
Trong sử dụng hàng ngày, các mô hình 3B đạt được sự cân bằng tối ưu. Bạn sẽ có một khoảng dừng ngắn khi xử lý, sau đó là đầu ra ổn định và hoàn toàn hữu ích cho việc soạn thảo hoặc hỗ trợ chung. Bạn có thể thử nghiệm với các mô hình 7B ở chế độ lượng tử hóa Q4 nếu muốn, nhưng hãy đặt kỳ vọng thực tế: chúng sẽ chậm hơn và ngốn bộ nhớ ảo nhiều hơn.
Ngoài ra, hãy giữ cửa sổ ngữ cảnh (context window) ở mức hợp lý. Khoảng 2k đến 4k token là vùng thoải mái trên các máy phân khúc này. Cũng cần nhớ rằng nhiều mô hình này có quá trình huấn luyện ngắn hơn đáng kể so với các 'ông lớn' như GPT, Gemini hay Copilot, nên đôi khi chúng sẽ cần những lời nhắc (prompts) rõ ràng hơn.
Sức hút của AI cục bộ trên Linux Mint: Hơn cả tốc độ
Điều khiến nhiều người ngạc nhiên nhất không phải là tốc độ xử lý thô, mà là cảm giác dễ sử dụng và ổn định của toàn bộ hệ thống sau khi các vấn đề nhỏ được giải quyết. Linux Mint vẫn là một nền tảng tuyệt vời cho loại thử nghiệm này: hỗ trợ phần cứng đã trưởng thành, nền tảng Ubuntu đảm bảo khả năng tương thích rộng, và môi trường Cinnamon duy trì sự mượt mà.
Với một chút tinh chỉnh và lựa chọn mô hình hợp lý, ngay cả một chiếc laptop tầm trung cũng có thể biến thành một trợ lý AI cục bộ mạnh mẽ. Các hệ thống LLM cục bộ không còn là đặc quyền của những máy trạm cao cấp. Với kỳ vọng đúng đắn và thiết lập cẩn thận, chúng cuối cùng đã nằm trong tầm tay của người dùng Linux thông thường.
Và phải nói rằng, có một sự thỏa mãn khó tả khi chứng kiến chính chiếc máy tính của mình tự xử lý các vấn đề, mang lại quyền kiểm soát và sự riêng tư mà các dịch vụ đám mây khó lòng sánh kịp.